Publications

Salient Facial Features from Humans and Deep Neural Networks S Sun*, WZ Teoh*, M Guerzhoy arXiv preprint arXiv:2003.08765
In this work, we explore the features that are used by humans and by ConvNets to classify faces. We use Guided Backpropagation to visualize the facial features that influence the output of a ConvNet the most when identifying specific individuals. we develop a human intelligence task to find out which facial features humans find to be the most important. We explore the differences between the saliency information gathered from humans and from ConvNets.
Paper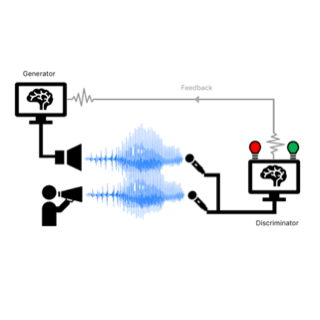
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis K Kumar, R Kumar, T de Boissiere, L Gestin, WZ Teoh, J Sotelo, A Brébisson, Y Bengio, A Courville Advances in Neural Information Processing Systems, 14881-892
We successfully train GANs to generate high quality coherent audio waveforms. We apply our models on the tasks of speech synthesis and music applications. Our model is non-autoregressive, with significantly fewer parameters than competing models and generalizes to unseen speakers for speech synthesis. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks.
Blog Post Paper Code